|
@@ -290,31 +290,32 @@ The path to data block 0 is even more quick, requiring only two jumps:
|
|
|
|
|
|
|
|
We can find the runtime complexity by looking at the path to any block from
|
|
We can find the runtime complexity by looking at the path to any block from
|
|
|
the block containing the most pointers. Every step along the path divides
|
|
the block containing the most pointers. Every step along the path divides
|
|
|
-the search space for the block in half. This gives us a runtime of O(log n).
|
|
|
|
|
|
|
+the search space for the block in half. This gives us a runtime of O(logn).
|
|
|
To get to the block with the most pointers, we can perform the same steps
|
|
To get to the block with the most pointers, we can perform the same steps
|
|
|
-backwards, which keeps the asymptotic runtime at O(log n). The interesting
|
|
|
|
|
|
|
+backwards, which puts the runtime at O(2logn) = O(logn). The interesting
|
|
|
part about this data structure is that this optimal path occurs naturally
|
|
part about this data structure is that this optimal path occurs naturally
|
|
|
if we greedily choose the pointer that covers the most distance without passing
|
|
if we greedily choose the pointer that covers the most distance without passing
|
|
|
our target block.
|
|
our target block.
|
|
|
|
|
|
|
|
So now we have a representation of files that can be appended trivially with
|
|
So now we have a representation of files that can be appended trivially with
|
|
|
-a runtime of O(1), and can be read with a worst case runtime of O(n logn).
|
|
|
|
|
|
|
+a runtime of O(1), and can be read with a worst case runtime of O(nlogn).
|
|
|
Given that the the runtime is also divided by the amount of data we can store
|
|
Given that the the runtime is also divided by the amount of data we can store
|
|
|
in a block, this is pretty reasonable.
|
|
in a block, this is pretty reasonable.
|
|
|
|
|
|
|
|
Unfortunately, the CTZ skip-list comes with a few questions that aren't
|
|
Unfortunately, the CTZ skip-list comes with a few questions that aren't
|
|
|
straightforward to answer. What is the overhead? How do we handle more
|
|
straightforward to answer. What is the overhead? How do we handle more
|
|
|
-pointers than we can store in a block?
|
|
|
|
|
|
|
+pointers than we can store in a block? How do we store the skip-list in
|
|
|
|
|
+a directory entry?
|
|
|
|
|
|
|
|
One way to find the overhead per block is to look at the data structure as
|
|
One way to find the overhead per block is to look at the data structure as
|
|
|
multiple layers of linked-lists. Each linked-list skips twice as many blocks
|
|
multiple layers of linked-lists. Each linked-list skips twice as many blocks
|
|
|
-as the previous linked-list. Or another way of looking at it is that each
|
|
|
|
|
|
|
+as the previous linked-list. Another way of looking at it is that each
|
|
|
linked-list uses half as much storage per block as the previous linked-list.
|
|
linked-list uses half as much storage per block as the previous linked-list.
|
|
|
As we approach infinity, the number of pointers per block forms a geometric
|
|
As we approach infinity, the number of pointers per block forms a geometric
|
|
|
series. Solving this geometric series gives us an average of only 2 pointers
|
|
series. Solving this geometric series gives us an average of only 2 pointers
|
|
|
per block.
|
|
per block.
|
|
|
|
|
|
|
|
-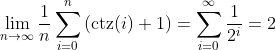
|
|
|
|
|
|
|
+
|
|
|
|
|
|
|
|
Finding the maximum number of pointers in a block is a bit more complicated,
|
|
Finding the maximum number of pointers in a block is a bit more complicated,
|
|
|
but since our file size is limited by the integer width we use to store the
|
|
but since our file size is limited by the integer width we use to store the
|
|
@@ -322,7 +323,7 @@ size, we can solve for it. Setting the overhead of the maximum pointers equal
|
|
|
to the block size we get the following equation. Note that a smaller block size
|
|
to the block size we get the following equation. Note that a smaller block size
|
|
|
results in more pointers, and a larger word width results in larger pointers.
|
|
results in more pointers, and a larger word width results in larger pointers.
|
|
|
|
|
|
|
|
-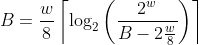
|
|
|
|
|
|
|
+
|
|
|
|
|
|
|
|
where:
|
|
where:
|
|
|
B = block size in bytes
|
|
B = block size in bytes
|
|
@@ -335,8 +336,102 @@ widths:
|
|
|
|
|
|
|
|
Since littlefs uses a 32 bit word size, we are limited to a minimum block
|
|
Since littlefs uses a 32 bit word size, we are limited to a minimum block
|
|
|
size of 104 bytes. This is a perfectly reasonable minimum block size, with most
|
|
size of 104 bytes. This is a perfectly reasonable minimum block size, with most
|
|
|
-block sizes starting around 512 bytes. So we can avoid the additional logic
|
|
|
|
|
-needed to avoid overflowing our block's capacity in the CTZ skip-list.
|
|
|
|
|
|
|
+block sizes starting around 512 bytes. So we can avoid additional logic to
|
|
|
|
|
+avoid overflowing our block's capacity in the CTZ skip-list.
|
|
|
|
|
+
|
|
|
|
|
+So, how do we store the skip-list in a directory entry? A naive approach would
|
|
|
|
|
+be to store a pointer to the head of the skip-list, the length of the file
|
|
|
|
|
+in bytes, the index of the head block in the skip-list, and the offset in the
|
|
|
|
|
+head block in bytes. However this is a lot of information, and we can observe
|
|
|
|
|
+that a file size maps to only one block index + offset pair. So it should be
|
|
|
|
|
+sufficient to store only the pointer and file size.
|
|
|
|
|
+
|
|
|
|
|
+But there is one problem, calculating the block index + offset pair from a
|
|
|
|
|
+file size doesn't have an obvious implementation.
|
|
|
|
|
+
|
|
|
|
|
+We can start by just writing down an equation. The first idea that comes to
|
|
|
|
|
+mind is to just use a for loop to sum together blocks until we reach our
|
|
|
|
|
+file size. We can write equation equation as a summation:
|
|
|
|
|
+
|
|
|
|
|
+
|
|
|
|
|
+
|
|
|
|
|
+where:
|
|
|
|
|
+B = block size in bytes
|
|
|
|
|
+w = word width in bits
|
|
|
|
|
+n = block index in skip-list
|
|
|
|
|
+N = file size in bytes
|
|
|
|
|
+
|
|
|
|
|
+And this works quite well, but is not trivial to calculate. This equation
|
|
|
|
|
+requires O(n) to compute, which brings the entire runtime of reading a file
|
|
|
|
|
+to O(n^2logn). Fortunately, the additional O(n) does not need to touch disk,
|
|
|
|
|
+so it is not completely unreasonable. But if we could solve this equation into
|
|
|
|
|
+a form that is easily computable, we can avoid a big slowdown.
|
|
|
|
|
+
|
|
|
|
|
+Unfortunately, the summation of the CTZ instruction presents a big challenge.
|
|
|
|
|
+How would you even begin to reason about integrating a bitwise instruction?
|
|
|
|
|
+Fortunately, there is a powerful tool I've found useful in these situations:
|
|
|
|
|
+The [On-Line Encyclopedia of Integer Sequences (OEIS)](https://oeis.org/).
|
|
|
|
|
+If we work out the first couple of values in our summation, we find that CTZ
|
|
|
|
|
+maps to [A001511](https://oeis.org/A001511), and its partial summation maps
|
|
|
|
|
+to [A005187](https://oeis.org/A005187), and surprisingly, both of these
|
|
|
|
|
+sequences have relatively trivial equations! This leads us to the completely
|
|
|
|
|
+unintuitive property:
|
|
|
|
|
+
|
|
|
|
|
+
|
|
|
|
|
+
|
|
|
|
|
+where:
|
|
|
|
|
+ctz(i) = the number of trailing bits that are 0 in i
|
|
|
|
|
+popcount(i) = the number of bits that are 1 in i
|
|
|
|
|
+
|
|
|
|
|
+I find it bewildering that these two seemingly unrelated bitwise instructions
|
|
|
|
|
+are related by this property. But if we start to disect this equation we can
|
|
|
|
|
+see that it does hold. As n approaches infinity, we do end up with an average
|
|
|
|
|
+overhead of 2 pointers as we find earlier. And popcount seems to handle the
|
|
|
|
|
+error from this average as it accumulates in the CTZ skip-list.
|
|
|
|
|
+
|
|
|
|
|
+Now we can substitute into the original equation to get a trivial equation
|
|
|
|
|
+for a file size:
|
|
|
|
|
+
|
|
|
|
|
+
|
|
|
|
|
+
|
|
|
|
|
+Unfortunately, we're not quite done. The popcount function is non-injective,
|
|
|
|
|
+so we can only find the file size from the block index, not the other way
|
|
|
|
|
+around. However, we can guess and correct. Consider an n' block index that
|
|
|
|
|
+is greater than n, we can find one pretty easily:
|
|
|
|
|
+
|
|
|
|
|
+
|
|
|
|
|
+
|
|
|
|
|
+where:
|
|
|
|
|
+n' >= n
|
|
|
|
|
+
|
|
|
|
|
+We can plug n' back into our popcount equation to find an N' file size that
|
|
|
|
|
+is greater than N. However, we need to rearrange our terms a bit to avoid
|
|
|
|
|
+integer overflow:
|
|
|
|
|
+
|
|
|
|
|
+
|
|
|
|
|
+
|
|
|
|
|
+where:
|
|
|
|
|
+N' >= N
|
|
|
|
|
+
|
|
|
|
|
+Now that we have N', we can find our block offset:
|
|
|
|
|
+
|
|
|
|
|
+
|
|
|
|
|
+
|
|
|
|
|
+where:
|
|
|
|
|
+off' >= off, our byte offset in the block
|
|
|
|
|
+
|
|
|
|
|
+Now we're getting somewhere. N' is greater than or equal to N, and as long as
|
|
|
|
|
+the number of pointers per block is bounded by the block size, it can only be
|
|
|
|
|
+different by at most one block. So we have two cases that can be determined by
|
|
|
|
|
+the sign of off'. If off' is negative, we correct n' and add a block to off'.
|
|
|
|
|
+Note that we also need to incorporate the overhead of the last block to get
|
|
|
|
|
+the right offset.
|
|
|
|
|
+
|
|
|
|
|
+
|
|
|
|
|
+
|
|
|
|
|
+It's a lot of math, but computers are very good at math. With these equations
|
|
|
|
|
+we can solve for the block index + offset while only needed to store the file
|
|
|
|
|
+size in O(1).
|
|
|
|
|
|
|
|
Here is what it might look like to update a file stored with a CTZ skip-list:
|
|
Here is what it might look like to update a file stored with a CTZ skip-list:
|
|
|
```
|
|
```
|
|
@@ -1129,7 +1224,7 @@ So, to summarize:
|
|
|
metadata block is active
|
|
metadata block is active
|
|
|
4. Directory blocks contain either references to other directories or files
|
|
4. Directory blocks contain either references to other directories or files
|
|
|
5. Files are represented by copy-on-write CTZ skip-lists which support O(1)
|
|
5. Files are represented by copy-on-write CTZ skip-lists which support O(1)
|
|
|
- append and O(n logn) reading
|
|
|
|
|
|
|
+ append and O(nlogn) reading
|
|
|
6. Blocks are allocated by scanning the filesystem for used blocks in a
|
|
6. Blocks are allocated by scanning the filesystem for used blocks in a
|
|
|
fixed-size lookahead region is that stored in a bit-vector
|
|
fixed-size lookahead region is that stored in a bit-vector
|
|
|
7. To facilitate scanning the filesystem, all directories are part of a
|
|
7. To facilitate scanning the filesystem, all directories are part of a
|

 Christopher Haster
Christopher Haster